
Notice
Recent Posts
Recent Comments
Link
| 일 | 월 | 화 | 수 | 목 | 금 | 토 |
|---|---|---|---|---|---|---|
| 1 | 2 | 3 | 4 | |||
| 5 | 6 | 7 | 8 | 9 | 10 | 11 |
| 12 | 13 | 14 | 15 | 16 | 17 | 18 |
| 19 | 20 | 21 | 22 | 23 | 24 | 25 |
| 26 | 27 | 28 | 29 | 30 | 31 |
Tags
- 편향-분산 교환
- window function
- 클라우드컴퓨팅
- L1정규화
- hackerrank
- PYTHON
- HTML
- branch
- full request
- 온라인협업
- merge
- 버전충돌
- AWS
- conflict
- 깃헙협업
- coding
- RLIKE
- 선형 모형
- 교차 엔트로피
- mysql
- elastic net
- early stopping
- github
- programmers
- L2정규화
- sql
- CSS
- 코딩공부
- Git
- leetcode
Archives
- Today
- Total
Im between cherry
감성 분석, 선형 모형, 로지스틱 회귀분석, 경사하강법, 교차 엔트로피 본문
1. 감성 분석
- 문장의 감성을 예측
- 감성: 긍/부정
- 찬성/반대, 좋다/싫다 등
- 기쁨, 슬픔, 분노 등은 정서라고 함
감성 분석의 방법
- 사전 기반
- 기계 학습 기반
사전 기반 감성 분석
- 단어 별로 긍/부정을 분류하여 감성 사전 만듦
- 긍정 단어의 예) 좋다, 만족한다, 뛰어나다
- 부정 단어의 예) 나쁘다, 불만이다, 뒤떨어진다
- 문장에서 긍정단어의 수와 부정단어의 수를 세서 많은 쪽으로 결정
감성 사전의 장단점
- 장점: 배경지식이 있다면 감정사전 만들 수 있음. 복잡한 프로그래밍 필요 없음. 우리가 가진 지식 활용 가능
- 단점: 해박한 배경지식이 필요. 사전으로 만드는데 많은 노력이 필요. 문장의 어순을 고려 못함
기계 학습의 장단점
- 장점: 감정 사전보다 성능이 높음. 배경지식이 불필요. 모형에 따라 문장의 어순도 고려할 수 있음. 감성 사전을 자동으로 만들 수도 있음
- 단점: 대량의 학습용 데이터가 필요. 학습용 데이터에 긍/부정으로 레이블을 붙이는데 많은 노력이 필요. 통계나 기계학습 지식이 필요
2. 선형 모형
선형 모형을 이용한 감성 분석
- 선형 모형 : y = wx + b
- x: 문서 내 특정 단어의 빈도
- y: 문서의 긍/부정(긍정=1, 부정=0)
- w: 가중치 또는 계수
- b: 절편 또는 편향
가중치에 따른 차이
- 가중치가 + : x가 증가할수록 y도 증가 -> 긍정 단어
- 가중치가 - : x가 증가하면 y는 감소 -> 부정 단어
3. 로지스틱 회귀분석
로지스틱 모형

- 선형 모형의 경우 y가 -∞ ~ +∞의 범위를 가짐
- 실제로 y는 긍정(1) 또는 부정(0)
- 선형 모형에 로지스틱함수를 결합하여 y가 0~1범위를 가지게 함
로지스틱 함수

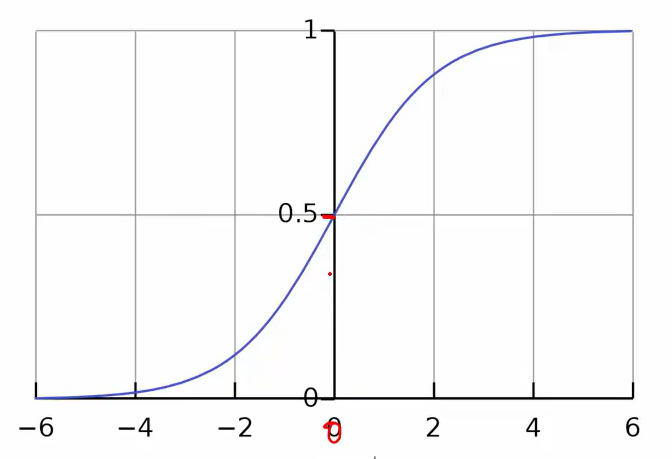
- 벨기에 수학자 P.F. 베르헐스트가 고안
- 기계학습에서는, S자 형태의 곡선이라 '시그모이드'라고도 함
- sigma: 그리스어의 S
- -oid: ~를 닮은(안드로이드: 인간을 닮은)
로지스틱 모형의 출력값에 대한 해석
- 로지스틱 모형은 0~1 사이의 실수를 출력 -> 확률로 해석
- ex) 0.8인 경우 -> 긍정일 확률 80% (부정일 확률 20%)
- 보통 0.5를 기준으로 그보다 높으면 긍정, 낮으면 부정으로 예측
4. 경사하강법
로지스틱 모형의 학습 방법
- '학습'이란 모형의 파라미터(w,b)를 추정하는 것
- 모형의 예측과 문장의 실제 긍/부정의 차이를 손실 함수로 측정, 손실 함수의 값을 가장 작게 만드는 파라미터르를 찾음 -> 차이에 따라 w와 b를 조정해준다.
- 중고등학교 때 배운것은 closed - form
- 머신러닝, 기계학습, 통계는 데이터가 완벽하지 않고 오차가 들어있기 때문에, 오차를 작게 하는게 중요한 open - form
- 주로 경사하강법(gradient descent)이라는 알고리즘을 사용
경사하강법의 원리
- 데이터의 일부(batch)를 모형에 입력
- 모형의 예측과 실제값을 비교하여 손실을 구함
- 손실이 작아지는 방향으로 파라미터를 약간 수정
- 위의 과정을 반복
5. 교차 엔트로피
교차 엔트로피
- 기계 학습에서 사용할 수 있는 손실함수에는 여러 종류가 있음
- 감성분석과 같이 0/1로 분류하는 문제일 경우, 교차 엔트로피를 손실 함수로 사용
- p와 q 두 확률 분포가 비슷할 수록 작아짐: y와 y^이 얼마나 비슷한지 보는 것

우도(likelihood)
- 어떤 모형 가정, 우리가 가진 샘플의 데이터가 관찰될 가능성
- 우도가 높으면, 우리의 가정이 맞다고 생각할 수 있음(최대우도법)
- 우도에 로그를 씌운 것이 로그 우도
- 로그 - 우도 최대화 = 교차 엔트로피 최소화
- 측정분포와 실제분포가 비슷하다
- w,b가 관찰될 가능성이 크다
'데이터분석 > 텍스트 데이터 분석' 카테고리의 다른 글
| 정규화, 노름, L1정규화, L2정규화, Elastic net, Early Stopping (0) | 2020.11.29 |
|---|---|
| 일반화, 용량, 과적합, 하이퍼파라미터, 검증, 편향-분산 교환 (0) | 2020.11.29 |
'데이터분석/텍스트 데이터 분석' Related Articles
more


Comments